GCC内联汇编
@source https://blog.csdn.net/hans774882968/article/details/127141703
https://bbs.kanxue.com/thread-279604.htm
https://blog.csdn.net/abel_big_xu/article/details/117927674
基本格式
1 | asm volatile( |
汇编语句必填,其它三部分可选
1 |
|
输出部分
表示当这段代码执行完后,对输出变量的约束。必要时在输出部分可以有多个约束,互相以逗号分隔。每个输出约束以=/+开头,跟着一个限定符表示操作数的类型(见下表)。
输入部分
当输出约束为空,若有输入约束,则必须保留分隔标记.
会被修改的部分
顾名思义
操作数
| 分类 | 限定符 | 描述 |
|---|---|---|
| 通用寄存器 | “a” | 将输入变量放入eax这里有一个问题:假设eax已经被使用,那怎么办?其实很简单:因为GCC 知道eax 已经被使用,它在这段汇编代码的起始处插入一条语句pushl %eax,将eax 内容保存到堆栈,然 后在这段代码结束处再增加一条语句popl %eax,恢复eax的内容 |
| “b” | 将输入变量放入ebx | |
| “c” | 将输入变量放入ecx | |
| “d” | 将输入变量放入edx | |
| “s” | 将输入变量放入esi | |
| “d” | 将输入变量放入edi | |
| “q” | 将输入变量放入eax,ebx,ecx,edx中的一个 | |
| “r” | 将输入变量放入通用寄存器,也就是eax,ebx,ecx,edx,esi,edi中的一个 | |
| “A” | 把eax和edx合成一个64 位的寄存器(use long longs) | |
| 内存 | “m” | 内存变量 |
| “o” | 操作数为内存变量,但是其寻址方式是偏移量类型,也即是基址寻址,或者是基址加变址寻址 | |
| “V” | 操作数为内存变量,但寻址方式不是偏移量类型 | |
| “ ” | 操作数为内存变量,但寻址方式为自动增量 | |
| “p” | 操作数是一个合法的内存地址(指针) | |
| 寄存器或内存 | “g” | 将输入变量放入eax,ebx,ecx,edx中的一个,或者作为内存变量 |
| “X” | 操作数可以是任何类型 | |
| 立即数 | “I” | 0-31之间的立即数(用于32位移位指令) |
| “J” | 0-63之间的立即数(用于64位移位指令) | |
| “N” | 0-255之间的立即数(用于out指令) | |
| “i” | 立即数 | |
| “n” | 立即数,有些系统不支持除字以外的立即数, 这些系统应该使用“n”而不是“i” | |
| 匹配 | “0”,“1”…“9” | 表示用它限制的操作数与某个指定的操作数匹配,也即该操作数就是指定的那个操作数,例如“0”去描述“%1”操作数,那么“%1”引用的其实就是“%0”操作数,注意作为限定符字母的0-9与指令中的“%0”-“%9”的区别,前者描述操作数,后者代表操作数。 |
| & | 该输出操作数不能使用过和输入操作数相同的寄存器 | |
| 操作数类型 | “=” | 操作数在指令中是只写的(输出操作数) |
| “+” | 操作数在指令中是读写类型的(输入输出操作数) | |
| 浮点数 | “f” | 浮点寄存器 |
| “t” | 第一个浮点寄存器 | |
| “u” | 第二个浮点寄存器 | |
| “G” | 标准的80387浮点常数 | |
| % | 该操作数可以和下一个操作数交换位置例如addl的两个操作数可以交换顺序(当然两个操作数都不能是立即数) | |
| # | 部分注释,从该字符到其后的逗号之间所有字母被忽略 | |
| * | 表示如果选用寄存器,则其后的字母被忽略c9ff95d8-f7d1-40e8-91a6-80c98643d2ea |
操作数的编号从输出部分的第一个约束开始顺序记数, 在汇编语句中引用这些操作数时用 %n 表示(n从0开始)
1 | __asm__ __volatile__("movl %1,%0" : "=r" (result) : "m" (input)); |
参数调用
1 | int main() |
1 | int main() |
改 Intel 风格
1 | asm( |
花指令
jnx + jx
1 | asm volatile( |
永真条件跳转
1 | asm volatile( |
1 | ; __unwind { |
重叠字节
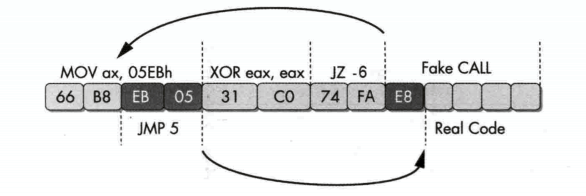
1 | asm volatile ( |
层面一:反汇编器看到的(静态分析)
反汇编器会从第一个字节 66 开始,顺序解析指令:
- **
66 B8 EB 05**:这是一条MOV指令。66:操作码前缀,表示操作数大小为 16 位。B8:MOV AX, imm16的操作码。EB 05:16 位立即数05EBh。- **指令:
mov ax, 05EBh**。这条指令将0x05EB移动到ax寄存器。
- **
31 C0**:这是一条XOR指令。31:XOR的操作码。C0:eax, eax的 ModR/M 字节。- **指令:
xor eax, eax**。这条指令将eax寄存器清零。
- **
74 FA**:这是一条JZ指令。74:JZ的操作码。FA:跳转偏移量-6。- **指令:
jz -6**。如果前一条指令结果为零,就向后跳转 6 个字节。
- **
E8**:这是一个CALL指令的操作码,但它在这里只被看作一个字节。
层面二:实际执行的(动态执行)
实际的程序执行流会是完全不同的。mov ax, 05EBh 的立即数部分被精心设计过,它包含了另一条指令:
- **
EB 05**:EB:jmp short的操作码。05:跳转偏移量+5。- **指令:
jmp +5**。当执行到这里时,程序会立即跳转到当前位置往后 5 个字节的地方。
因此,实际执行流是:
mov ax, 05EBh执行时,会跳过后面的xor eax, eax和jz -/3指令。- 程序跳转到
E8所在的位置。 E8字节被解释为call指令的操作码。它会调用Real Code,然后Real Code执行完毕后返回,程序继续正常执行。